Gradient descent versus normal equation
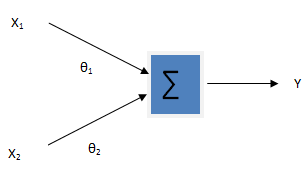
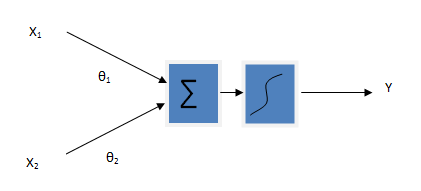
Gradient descent and normal equation (also called batch processing) both are methods for finding out the local minimum of a function. I have given some intuition about gradient descent in previous article. Gradient descent is actually an iterative method to find out the parameters. We start with the initial guess of the parameters (usually zeros but not necessarily), and gradually adjust those parameters so that we get the function that best fit the given data points. Here is the mathematical formulation of gradient descent in the case of linear regression.
\[ J(\theta_0,\theta_1) = \frac 1 {2m} \sum_{i=1}^m (h_\theta(x^{(i)}) – y^{(i)})^2 …….. (1) \]
Taking the partial derivative w.r.t θ0 and θ1
\[ \frac {\partial J(\theta_0,\theta1)}{\partial \theta_0} = \frac 1 {m} \sum_{i=1}^m(h_\theta(x^{(i)}) – y^{(i)}) \\
\frac {\partial J(\theta_0,\theta1)}{\partial \theta_1} = \frac 1 {m} \sum_{i=1}^m(h_\theta(x^{(i)}) – y^{(i)}).x^{(i)} \]
These equations gives the slopes of (1) at points theta0 and theta1. To minimize (1), we subtract or add the slopes from parameters depending upon whether slopes are decreasing or increasing. If increasing, we subtract and if decreasing we add the slopes so that we reach to the local minimum. To control the speed of convergence, we generally multiply slope with a parameter also called learning parameter and is denoted by α. So, we perform the following two operations until reach a condition at which two consecutive values of parameters are same or nearly same.
\[ \theta_0 := \theta_0 – \alpha \frac 1 {m} \sum_{i=1}^m (h_\theta(x^{(i)}) – y^{(i)}) \\
\theta_1 := \theta_1 – \alpha \frac 1 {m} \sum_{i=1}^m (h_\theta(x^{(i)}) – y^{(i)}).x^{(i)} \]
The normal equation is slightly different than the gradient descent. Normal equation finds out the parameter in a single step involving matrix inversion and other expensive matrix operations. The beauty behind the normal equation is it calculates the parameters using the analytical approach in a single step. You don’t need the learning parameter and number of iterations (and other stopping criteria). The feature space (i.e. feature matrix), output vector (considering supervised learning) and matrix operations among them are sufficient for calculating the parameters.
Mathematically the normal equation is given by
\[\theta = (X^TX)^{-1}X^Ty\]
Where X is a n x (m+1) dimensional feature matrix containing m features and n variables and y is the output vector. Here is the derivation of Normal equation.
\[ \sum err^2 = \sum (y_{predicted} – y_{actual}))^2
\\ \sum err_i^2 = \sum (y_i – (\theta_0 + \theta_1x_{i1} + \theta_2x_{i2}))^2 \]
The partial derivative should be zero for error minimization i.e.
\[ \frac {\partial \sum err_i^2 }{\partial (\theta_k)} = 0 \]
For k = 0, 1, 2, we get
\[ \sum 2(y_i – (\theta_0 + \theta_1x_{i1} + \theta_2x_{i2}).(-1) = 0
\\ \sum 2(y_i – (\theta_0 + \theta_1x_{i1} + \theta_2x_{i2}).(-x_{i1}) = 0
\\ \sum 2(y_i – (\theta_0 + \theta_1x_{i1} + \theta_2x_{i2}).(-x_{i2}) = 0 \]
Simplification results
\[ \sum y_i = n\theta_0 + \theta_1 \sum x_{i1} + \theta_2 \sum x_{i2}
\\ \sum x_{1i}y_i = \theta_0 \sum x_{i1} + \theta_1 \sum x_{i1}x_{i1} + \theta_2 \sum x_{i1}x_{i2}
\\ \sum x_{2i}y_i = \theta_0 \sum x_{i2} + \theta_1 \sum x_{i1}x_{i2} + \theta_2 \sum x_{i2}x_{i2} \]
Expressing these equations in matrix form
\[\begin{pmatrix}
1 & 1 & 1 \\
x_{11} & x_{21} & x_{31} \\
x_{12} & x_{22} & x_{32}
\end{pmatrix} \begin{pmatrix}
y_1 \\
y_2 \\
y_3
\end{pmatrix} =
\begin{pmatrix}
1 & 1 & 1 \\
x_{11} & x_{21} & x_{31} \\
x_{12} & x_{22} & x_{32}
\end{pmatrix} \begin{pmatrix}
1 & x_{11} & x_{12} \\
1 & x_{21} & x_{22} \\
1 & x_{31} & x_{32}
\end{pmatrix}\begin{pmatrix}
\theta_0 \\
\theta_1 \\
\theta_2
\end{pmatrix}
\]
\[ X^Ty = X^TX\theta \\
(XX^T)^{-1}X^Ty = (XX^T)^{-1} X^TX\theta \\
\theta = (X^TX)^{-1}X^Ty\]
But, as the number of features (i.e. dimension) increases, the Normal equation’s performance gradually decreases. This is because of the expensive matrix operations. That is way gradient descent is preferred over normal equation in most of the machine learning problem involving large number of features.
As a concluding remark, use the Normal equation when the number of features is relatively small (in hundreds or sometimes thousands) and if #features are very large (in millions ) choose the gradient descent.
Note
There are various other optimization techniques besides gradient descent and normal equation. These are actually very basic techniques for minimization using least square method. If you want to learn more about mathematical optimization then check out the wikipedia page. There is very nice optimization library in python. Python developer can look into it

Hi Bibek Subedi I am very thankful to you , It is really important blog all the programmer . i have read lot of post from this blog. i am using this site for know codding and help etc. nice work